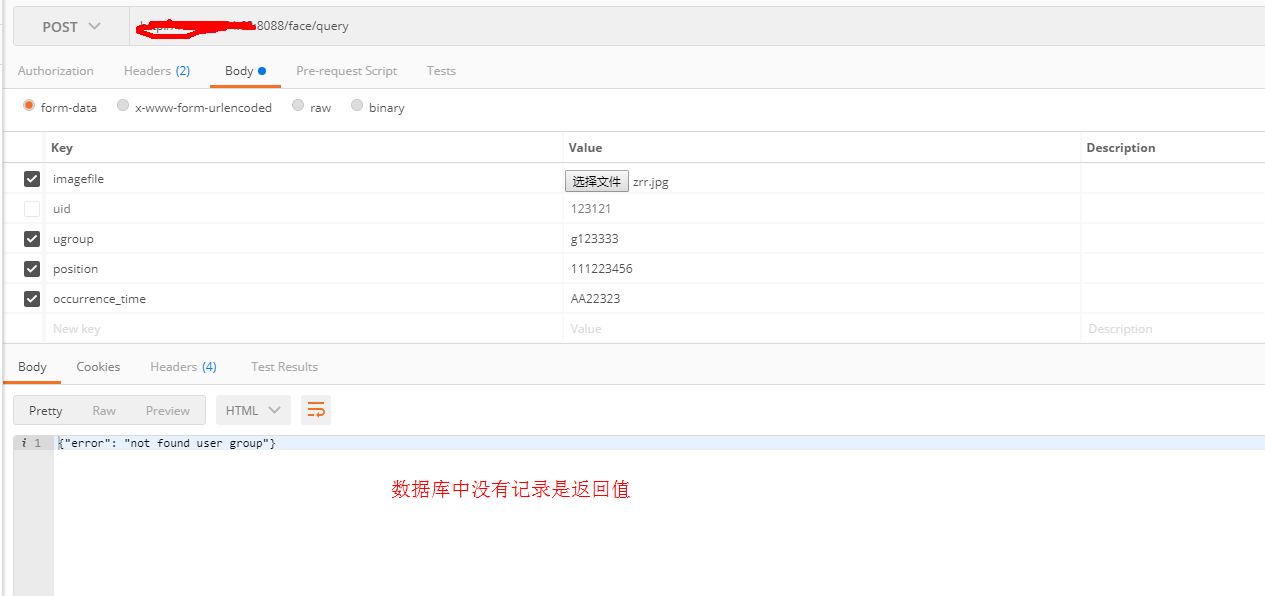
|
|
@@ -0,0 +1,778 @@
|
|
|
+""" Tensorflow implementation of the face detection / alignment algorithm found at
|
|
|
+https://github.com/kpzhang93/MTCNN_face_detection_alignment
|
|
|
+"""
|
|
|
+# MIT License
|
|
|
+#
|
|
|
+# Copyright (c) 2016 David Sandberg
|
|
|
+#
|
|
|
+# Permission is hereby granted, free of charge, to any person obtaining a copy
|
|
|
+# of this software and associated documentation files (the "Software"), to deal
|
|
|
+# in the Software without restriction, including without limitation the rights
|
|
|
+# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
|
|
+# copies of the Software, and to permit persons to whom the Software is
|
|
|
+# furnished to do so, subject to the following conditions:
|
|
|
+#
|
|
|
+# The above copyright notice and this permission notice shall be included in all
|
|
|
+# copies or substantial portions of the Software.
|
|
|
+#
|
|
|
+# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
|
|
+# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
|
|
+# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
|
|
+# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
|
|
+# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
|
|
+# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
|
|
+# SOFTWARE.
|
|
|
+
|
|
|
+from __future__ import absolute_import
|
|
|
+from __future__ import division
|
|
|
+from __future__ import print_function
|
|
|
+from six import string_types, iteritems
|
|
|
+
|
|
|
+import numpy as np
|
|
|
+import tensorflow as tf
|
|
|
+#from math import floor
|
|
|
+import cv2
|
|
|
+import os
|
|
|
+
|
|
|
+def layer(op):
|
|
|
+ '''Decorator for composable network layers.'''
|
|
|
+
|
|
|
+ def layer_decorated(self, *args, **kwargs):
|
|
|
+ # Automatically set a name if not provided.
|
|
|
+ name = kwargs.setdefault('name', self.get_unique_name(op.__name__))
|
|
|
+ # Figure out the layer inputs.
|
|
|
+ if len(self.terminals) == 0:
|
|
|
+ raise RuntimeError('No input variables found for layer %s.' % name)
|
|
|
+ elif len(self.terminals) == 1:
|
|
|
+ layer_input = self.terminals[0]
|
|
|
+ else:
|
|
|
+ layer_input = list(self.terminals)
|
|
|
+ # Perform the operation and get the output.
|
|
|
+ layer_output = op(self, layer_input, *args, **kwargs)
|
|
|
+ # Add to layer LUT.
|
|
|
+ self.layers[name] = layer_output
|
|
|
+ # This output is now the input for the next layer.
|
|
|
+ self.feed(layer_output)
|
|
|
+ # Return self for chained calls.
|
|
|
+ return self
|
|
|
+
|
|
|
+ return layer_decorated
|
|
|
+
|
|
|
+class Network(object):
|
|
|
+
|
|
|
+ def __init__(self, inputs, trainable=True):
|
|
|
+ # The input nodes for this network
|
|
|
+ self.inputs = inputs
|
|
|
+ # The current list of terminal nodes
|
|
|
+ self.terminals = []
|
|
|
+ # Mapping from layer names to layers
|
|
|
+ self.layers = dict(inputs)
|
|
|
+ # If true, the resulting variables are set as trainable
|
|
|
+ self.trainable = trainable
|
|
|
+
|
|
|
+ self.setup()
|
|
|
+
|
|
|
+ def setup(self):
|
|
|
+ '''Construct the network. '''
|
|
|
+ raise NotImplementedError('Must be implemented by the subclass.')
|
|
|
+
|
|
|
+ def load(self, data_path, session, ignore_missing=False):
|
|
|
+ '''Load network weights.
|
|
|
+ data_path: The path to the numpy-serialized network weights
|
|
|
+ session: The current TensorFlow session
|
|
|
+ ignore_missing: If true, serialized weights for missing layers are ignored.
|
|
|
+ '''
|
|
|
+ data_dict = np.load(data_path, encoding='latin1').item() #pylint: disable=no-member
|
|
|
+
|
|
|
+ for op_name in data_dict:
|
|
|
+ with tf.variable_scope(op_name, reuse=True):
|
|
|
+ for param_name, data in iteritems(data_dict[op_name]):
|
|
|
+ try:
|
|
|
+ var = tf.get_variable(param_name)
|
|
|
+ session.run(var.assign(data))
|
|
|
+ except ValueError:
|
|
|
+ if not ignore_missing:
|
|
|
+ raise
|
|
|
+
|
|
|
+ def feed(self, *args):
|
|
|
+ '''Set the input(s) for the next operation by replacing the terminal nodes.
|
|
|
+ The arguments can be either layer names or the actual layers.
|
|
|
+ '''
|
|
|
+ assert len(args) != 0
|
|
|
+ self.terminals = []
|
|
|
+ for fed_layer in args:
|
|
|
+ if isinstance(fed_layer, string_types):
|
|
|
+ try:
|
|
|
+ fed_layer = self.layers[fed_layer]
|
|
|
+ except KeyError:
|
|
|
+ raise KeyError('Unknown layer name fed: %s' % fed_layer)
|
|
|
+ self.terminals.append(fed_layer)
|
|
|
+ return self
|
|
|
+
|
|
|
+ def get_output(self):
|
|
|
+ '''Returns the current network output.'''
|
|
|
+ return self.terminals[-1]
|
|
|
+
|
|
|
+ def get_unique_name(self, prefix):
|
|
|
+ '''Returns an index-suffixed unique name for the given prefix.
|
|
|
+ This is used for auto-generating layer names based on the type-prefix.
|
|
|
+ '''
|
|
|
+ ident = sum(t.startswith(prefix) for t, _ in self.layers.items()) + 1
|
|
|
+ return '%s_%d' % (prefix, ident)
|
|
|
+
|
|
|
+ def make_var(self, name, shape):
|
|
|
+ '''Creates a new TensorFlow variable.'''
|
|
|
+ return tf.get_variable(name, shape, trainable=self.trainable)
|
|
|
+
|
|
|
+ def validate_padding(self, padding):
|
|
|
+ '''Verifies that the padding is one of the supported ones.'''
|
|
|
+ assert padding in ('SAME', 'VALID')
|
|
|
+
|
|
|
+ @layer
|
|
|
+ def conv(self,
|
|
|
+ inp,
|
|
|
+ k_h,
|
|
|
+ k_w,
|
|
|
+ c_o,
|
|
|
+ s_h,
|
|
|
+ s_w,
|
|
|
+ name,
|
|
|
+ relu=True,
|
|
|
+ padding='SAME',
|
|
|
+ group=1,
|
|
|
+ biased=True):
|
|
|
+ # Verify that the padding is acceptable
|
|
|
+ self.validate_padding(padding)
|
|
|
+ # Get the number of channels in the input
|
|
|
+ c_i = int(inp.get_shape()[-1])
|
|
|
+ # Verify that the grouping parameter is valid
|
|
|
+ assert c_i % group == 0
|
|
|
+ assert c_o % group == 0
|
|
|
+ # Convolution for a given input and kernel
|
|
|
+ convolve = lambda i, k: tf.nn.conv2d(i, k, [1, s_h, s_w, 1], padding=padding)
|
|
|
+ with tf.variable_scope(name) as scope:
|
|
|
+ kernel = self.make_var('weights', shape=[k_h, k_w, c_i // group, c_o])
|
|
|
+ # This is the common-case. Convolve the input without any further complications.
|
|
|
+ output = convolve(inp, kernel)
|
|
|
+ # Add the biases
|
|
|
+ if biased:
|
|
|
+ biases = self.make_var('biases', [c_o])
|
|
|
+ output = tf.nn.bias_add(output, biases)
|
|
|
+ if relu:
|
|
|
+ # ReLU non-linearity
|
|
|
+ output = tf.nn.relu(output, name=scope.name)
|
|
|
+ return output
|
|
|
+
|
|
|
+ @layer
|
|
|
+ def prelu(self, inp, name):
|
|
|
+ with tf.variable_scope(name):
|
|
|
+ i = int(inp.get_shape()[-1])
|
|
|
+ alpha = self.make_var('alpha', shape=(i,))
|
|
|
+ output = tf.nn.relu(inp) + tf.multiply(alpha, -tf.nn.relu(-inp))
|
|
|
+ return output
|
|
|
+
|
|
|
+ @layer
|
|
|
+ def max_pool(self, inp, k_h, k_w, s_h, s_w, name, padding='SAME'):
|
|
|
+ self.validate_padding(padding)
|
|
|
+ return tf.nn.max_pool(inp,
|
|
|
+ ksize=[1, k_h, k_w, 1],
|
|
|
+ strides=[1, s_h, s_w, 1],
|
|
|
+ padding=padding,
|
|
|
+ name=name)
|
|
|
+
|
|
|
+ @layer
|
|
|
+ def fc(self, inp, num_out, name, relu=True):
|
|
|
+ with tf.variable_scope(name):
|
|
|
+ input_shape = inp.get_shape()
|
|
|
+ if input_shape.ndims == 4:
|
|
|
+ # The input is spatial. Vectorize it first.
|
|
|
+ dim = 1
|
|
|
+ for d in input_shape[1:].as_list():
|
|
|
+ dim *= int(d)
|
|
|
+ feed_in = tf.reshape(inp, [-1, dim])
|
|
|
+ else:
|
|
|
+ feed_in, dim = (inp, input_shape[-1].value)
|
|
|
+ weights = self.make_var('weights', shape=[dim, num_out])
|
|
|
+ biases = self.make_var('biases', [num_out])
|
|
|
+ op = tf.nn.relu_layer if relu else tf.nn.xw_plus_b
|
|
|
+ fc = op(feed_in, weights, biases, name=name)
|
|
|
+ return fc
|
|
|
+
|
|
|
+
|
|
|
+ """
|
|
|
+ Multi dimensional softmax,
|
|
|
+ refer to https://github.com/tensorflow/tensorflow/issues/210
|
|
|
+ compute softmax along the dimension of target
|
|
|
+ the native softmax only supports batch_size x dimension
|
|
|
+ """
|
|
|
+ @layer
|
|
|
+ def softmax(self, target, axis, name=None):
|
|
|
+ max_axis = tf.reduce_max(target, axis, keep_dims=True)
|
|
|
+ target_exp = tf.exp(target-max_axis)
|
|
|
+ normalize = tf.reduce_sum(target_exp, axis, keep_dims=True)
|
|
|
+ softmax = tf.div(target_exp, normalize, name)
|
|
|
+ return softmax
|
|
|
+
|
|
|
+class PNet(Network):
|
|
|
+ def setup(self):
|
|
|
+ (self.feed('data') #pylint: disable=no-value-for-parameter, no-member
|
|
|
+ .conv(3, 3, 10, 1, 1, padding='VALID', relu=False, name='conv1')
|
|
|
+ .prelu(name='PReLU1')
|
|
|
+ .max_pool(2, 2, 2, 2, name='pool1')
|
|
|
+ .conv(3, 3, 16, 1, 1, padding='VALID', relu=False, name='conv2')
|
|
|
+ .prelu(name='PReLU2')
|
|
|
+ .conv(3, 3, 32, 1, 1, padding='VALID', relu=False, name='conv3')
|
|
|
+ .prelu(name='PReLU3')
|
|
|
+ .conv(1, 1, 2, 1, 1, relu=False, name='conv4-1')
|
|
|
+ .softmax(3,name='prob1'))
|
|
|
+
|
|
|
+ (self.feed('PReLU3') #pylint: disable=no-value-for-parameter
|
|
|
+ .conv(1, 1, 4, 1, 1, relu=False, name='conv4-2'))
|
|
|
+
|
|
|
+class RNet(Network):
|
|
|
+ def setup(self):
|
|
|
+ (self.feed('data') #pylint: disable=no-value-for-parameter, no-member
|
|
|
+ .conv(3, 3, 28, 1, 1, padding='VALID', relu=False, name='conv1')
|
|
|
+ .prelu(name='prelu1')
|
|
|
+ .max_pool(3, 3, 2, 2, name='pool1')
|
|
|
+ .conv(3, 3, 48, 1, 1, padding='VALID', relu=False, name='conv2')
|
|
|
+ .prelu(name='prelu2')
|
|
|
+ .max_pool(3, 3, 2, 2, padding='VALID', name='pool2')
|
|
|
+ .conv(2, 2, 64, 1, 1, padding='VALID', relu=False, name='conv3')
|
|
|
+ .prelu(name='prelu3')
|
|
|
+ .fc(128, relu=False, name='conv4')
|
|
|
+ .prelu(name='prelu4')
|
|
|
+ .fc(2, relu=False, name='conv5-1')
|
|
|
+ .softmax(1,name='prob1'))
|
|
|
+
|
|
|
+ (self.feed('prelu4') #pylint: disable=no-value-for-parameter
|
|
|
+ .fc(4, relu=False, name='conv5-2'))
|
|
|
+
|
|
|
+class ONet(Network):
|
|
|
+ def setup(self):
|
|
|
+ (self.feed('data') #pylint: disable=no-value-for-parameter, no-member
|
|
|
+ .conv(3, 3, 32, 1, 1, padding='VALID', relu=False, name='conv1')
|
|
|
+ .prelu(name='prelu1')
|
|
|
+ .max_pool(3, 3, 2, 2, name='pool1')
|
|
|
+ .conv(3, 3, 64, 1, 1, padding='VALID', relu=False, name='conv2')
|
|
|
+ .prelu(name='prelu2')
|
|
|
+ .max_pool(3, 3, 2, 2, padding='VALID', name='pool2')
|
|
|
+ .conv(3, 3, 64, 1, 1, padding='VALID', relu=False, name='conv3')
|
|
|
+ .prelu(name='prelu3')
|
|
|
+ .max_pool(2, 2, 2, 2, name='pool3')
|
|
|
+ .conv(2, 2, 128, 1, 1, padding='VALID', relu=False, name='conv4')
|
|
|
+ .prelu(name='prelu4')
|
|
|
+ .fc(256, relu=False, name='conv5')
|
|
|
+ .prelu(name='prelu5')
|
|
|
+ .fc(2, relu=False, name='conv6-1')
|
|
|
+ .softmax(1, name='prob1'))
|
|
|
+
|
|
|
+ (self.feed('prelu5') #pylint: disable=no-value-for-parameter
|
|
|
+ .fc(4, relu=False, name='conv6-2'))
|
|
|
+
|
|
|
+ (self.feed('prelu5') #pylint: disable=no-value-for-parameter
|
|
|
+ .fc(10, relu=False, name='conv6-3'))
|
|
|
+
|
|
|
+def create_mtcnn(sess, model_path):
|
|
|
+ if not model_path:
|
|
|
+ model_path,_ = os.path.split(os.path.realpath(__file__))
|
|
|
+
|
|
|
+ with tf.variable_scope('pnet'):
|
|
|
+ data = tf.placeholder(tf.float32, (None,None,None,3), 'input')
|
|
|
+ pnet = PNet({'data':data})
|
|
|
+ pnet.load(os.path.join(model_path, 'det1.npy'), sess)
|
|
|
+ with tf.variable_scope('rnet'):
|
|
|
+ data = tf.placeholder(tf.float32, (None,24,24,3), 'input')
|
|
|
+ rnet = RNet({'data':data})
|
|
|
+ rnet.load(os.path.join(model_path, 'det2.npy'), sess)
|
|
|
+ with tf.variable_scope('onet'):
|
|
|
+ data = tf.placeholder(tf.float32, (None,48,48,3), 'input')
|
|
|
+ onet = ONet({'data':data})
|
|
|
+ onet.load(os.path.join(model_path, 'det3.npy'), sess)
|
|
|
+
|
|
|
+ pnet_fun = lambda img : sess.run(('pnet/conv4-2/BiasAdd:0', 'pnet/prob1:0'), feed_dict={'pnet/input:0':img})
|
|
|
+ rnet_fun = lambda img : sess.run(('rnet/conv5-2/conv5-2:0', 'rnet/prob1:0'), feed_dict={'rnet/input:0':img})
|
|
|
+ onet_fun = lambda img : sess.run(('onet/conv6-2/conv6-2:0', 'onet/conv6-3/conv6-3:0', 'onet/prob1:0'), feed_dict={'onet/input:0':img})
|
|
|
+ return pnet_fun, rnet_fun, onet_fun
|
|
|
+
|
|
|
+def detect_face(img, minsize, pnet, rnet, onet, threshold, factor):
|
|
|
+ # im: input image
|
|
|
+ # minsize: minimum of faces' size
|
|
|
+ # pnet, rnet, onet: caffemodel
|
|
|
+ # threshold: threshold=[th1 th2 th3], th1-3 are three steps's threshold
|
|
|
+ # fastresize: resize img from last scale (using in high-resolution images) if fastresize==true
|
|
|
+ factor_count=0
|
|
|
+ total_boxes=np.empty((0,9))
|
|
|
+ points=np.empty(0)
|
|
|
+ h=img.shape[0]
|
|
|
+ w=img.shape[1]
|
|
|
+ minl=np.amin([h, w])
|
|
|
+ m=12.0/minsize
|
|
|
+ minl=minl*m
|
|
|
+ # creat scale pyramid
|
|
|
+ scales=[]
|
|
|
+ while minl>=12:
|
|
|
+ scales += [m*np.power(factor, factor_count)]
|
|
|
+ minl = minl*factor
|
|
|
+ factor_count += 1
|
|
|
+
|
|
|
+ # first stage
|
|
|
+ for j in range(len(scales)):
|
|
|
+ scale=scales[j]
|
|
|
+ hs=int(np.ceil(h*scale))
|
|
|
+ ws=int(np.ceil(w*scale))
|
|
|
+ im_data = imresample(img, (hs, ws))
|
|
|
+ im_data = (im_data-127.5)*0.0078125
|
|
|
+ img_x = np.expand_dims(im_data, 0)
|
|
|
+ img_y = np.transpose(img_x, (0,2,1,3))
|
|
|
+ out = pnet(img_y)
|
|
|
+ out0 = np.transpose(out[0], (0,2,1,3))
|
|
|
+ out1 = np.transpose(out[1], (0,2,1,3))
|
|
|
+
|
|
|
+ boxes, _ = generateBoundingBox(out1[0,:,:,1].copy(), out0[0,:,:,:].copy(), scale, threshold[0])
|
|
|
+
|
|
|
+ # inter-scale nms
|
|
|
+ pick = nms(boxes.copy(), 0.5, 'Union')
|
|
|
+ if boxes.size>0 and pick.size>0:
|
|
|
+ boxes = boxes[pick,:]
|
|
|
+ total_boxes = np.append(total_boxes, boxes, axis=0)
|
|
|
+
|
|
|
+ numbox = total_boxes.shape[0]
|
|
|
+ if numbox>0:
|
|
|
+ pick = nms(total_boxes.copy(), 0.7, 'Union')
|
|
|
+ total_boxes = total_boxes[pick,:]
|
|
|
+ regw = total_boxes[:,2]-total_boxes[:,0]
|
|
|
+ regh = total_boxes[:,3]-total_boxes[:,1]
|
|
|
+ qq1 = total_boxes[:,0]+total_boxes[:,5]*regw
|
|
|
+ qq2 = total_boxes[:,1]+total_boxes[:,6]*regh
|
|
|
+ qq3 = total_boxes[:,2]+total_boxes[:,7]*regw
|
|
|
+ qq4 = total_boxes[:,3]+total_boxes[:,8]*regh
|
|
|
+ total_boxes = np.transpose(np.vstack([qq1, qq2, qq3, qq4, total_boxes[:,4]]))
|
|
|
+ total_boxes = rerec(total_boxes.copy())
|
|
|
+ total_boxes[:,0:4] = np.fix(total_boxes[:,0:4]).astype(np.int32)
|
|
|
+ dy, edy, dx, edx, y, ey, x, ex, tmpw, tmph = pad(total_boxes.copy(), w, h)
|
|
|
+
|
|
|
+ numbox = total_boxes.shape[0]
|
|
|
+ if numbox>0:
|
|
|
+ # second stage
|
|
|
+ tempimg = np.zeros((24,24,3,numbox))
|
|
|
+ for k in range(0,numbox):
|
|
|
+ tmp = np.zeros((int(tmph[k]),int(tmpw[k]),3))
|
|
|
+ tmp[dy[k]-1:edy[k],dx[k]-1:edx[k],:] = img[y[k]-1:ey[k],x[k]-1:ex[k],:]
|
|
|
+ if tmp.shape[0]>0 and tmp.shape[1]>0 or tmp.shape[0]==0 and tmp.shape[1]==0:
|
|
|
+ tempimg[:,:,:,k] = imresample(tmp, (24, 24))
|
|
|
+ else:
|
|
|
+ return np.empty()
|
|
|
+ tempimg = (tempimg-127.5)*0.0078125
|
|
|
+ tempimg1 = np.transpose(tempimg, (3,1,0,2))
|
|
|
+ out = rnet(tempimg1)
|
|
|
+ out0 = np.transpose(out[0])
|
|
|
+ out1 = np.transpose(out[1])
|
|
|
+ score = out1[1,:]
|
|
|
+ ipass = np.where(score>threshold[1])
|
|
|
+ total_boxes = np.hstack([total_boxes[ipass[0],0:4].copy(), np.expand_dims(score[ipass].copy(),1)])
|
|
|
+ mv = out0[:,ipass[0]]
|
|
|
+ if total_boxes.shape[0]>0:
|
|
|
+ pick = nms(total_boxes, 0.7, 'Union')
|
|
|
+ total_boxes = total_boxes[pick,:]
|
|
|
+ total_boxes = bbreg(total_boxes.copy(), np.transpose(mv[:,pick]))
|
|
|
+ total_boxes = rerec(total_boxes.copy())
|
|
|
+
|
|
|
+ numbox = total_boxes.shape[0]
|
|
|
+ if numbox>0:
|
|
|
+ # third stage
|
|
|
+ total_boxes = np.fix(total_boxes).astype(np.int32)
|
|
|
+ dy, edy, dx, edx, y, ey, x, ex, tmpw, tmph = pad(total_boxes.copy(), w, h)
|
|
|
+ tempimg = np.zeros((48,48,3,numbox))
|
|
|
+ for k in range(0,numbox):
|
|
|
+ tmp = np.zeros((int(tmph[k]),int(tmpw[k]),3))
|
|
|
+ tmp[dy[k]-1:edy[k],dx[k]-1:edx[k],:] = img[y[k]-1:ey[k],x[k]-1:ex[k],:]
|
|
|
+ if tmp.shape[0]>0 and tmp.shape[1]>0 or tmp.shape[0]==0 and tmp.shape[1]==0:
|
|
|
+ tempimg[:,:,:,k] = imresample(tmp, (48, 48))
|
|
|
+ else:
|
|
|
+ return np.empty()
|
|
|
+ tempimg = (tempimg-127.5)*0.0078125
|
|
|
+ tempimg1 = np.transpose(tempimg, (3,1,0,2))
|
|
|
+ out = onet(tempimg1)
|
|
|
+ out0 = np.transpose(out[0])
|
|
|
+ out1 = np.transpose(out[1])
|
|
|
+ out2 = np.transpose(out[2])
|
|
|
+ score = out2[1,:]
|
|
|
+ points = out1
|
|
|
+ ipass = np.where(score>threshold[2])
|
|
|
+ points = points[:,ipass[0]]
|
|
|
+ total_boxes = np.hstack([total_boxes[ipass[0],0:4].copy(), np.expand_dims(score[ipass].copy(),1)])
|
|
|
+ mv = out0[:,ipass[0]]
|
|
|
+
|
|
|
+ w = total_boxes[:,2]-total_boxes[:,0]+1
|
|
|
+ h = total_boxes[:,3]-total_boxes[:,1]+1
|
|
|
+ points[0:5,:] = np.tile(w,(5, 1))*points[0:5,:] + np.tile(total_boxes[:,0],(5, 1))-1
|
|
|
+ points[5:10,:] = np.tile(h,(5, 1))*points[5:10,:] + np.tile(total_boxes[:,1],(5, 1))-1
|
|
|
+ if total_boxes.shape[0]>0:
|
|
|
+ total_boxes = bbreg(total_boxes.copy(), np.transpose(mv))
|
|
|
+ pick = nms(total_boxes.copy(), 0.7, 'Min')
|
|
|
+ total_boxes = total_boxes[pick,:]
|
|
|
+ points = points[:,pick]
|
|
|
+
|
|
|
+ return total_boxes, points
|
|
|
+
|
|
|
+
|
|
|
+def bulk_detect_face(images, detection_window_size_ratio, pnet, rnet, onet, threshold, factor):
|
|
|
+ # im: input image
|
|
|
+ # minsize: minimum of faces' size
|
|
|
+ # pnet, rnet, onet: caffemodel
|
|
|
+ # threshold: threshold=[th1 th2 th3], th1-3 are three steps's threshold [0-1]
|
|
|
+
|
|
|
+ all_scales = [None] * len(images)
|
|
|
+ images_with_boxes = [None] * len(images)
|
|
|
+
|
|
|
+ for i in range(len(images)):
|
|
|
+ images_with_boxes[i] = {'total_boxes': np.empty((0, 9))}
|
|
|
+
|
|
|
+ # create scale pyramid
|
|
|
+ for index, img in enumerate(images):
|
|
|
+ all_scales[index] = []
|
|
|
+ h = img.shape[0]
|
|
|
+ w = img.shape[1]
|
|
|
+ minsize = int(detection_window_size_ratio * np.minimum(w, h))
|
|
|
+ factor_count = 0
|
|
|
+ minl = np.amin([h, w])
|
|
|
+ if minsize <= 12:
|
|
|
+ minsize = 12
|
|
|
+
|
|
|
+ m = 12.0 / minsize
|
|
|
+ minl = minl * m
|
|
|
+ while minl >= 12:
|
|
|
+ all_scales[index].append(m * np.power(factor, factor_count))
|
|
|
+ minl = minl * factor
|
|
|
+ factor_count += 1
|
|
|
+
|
|
|
+ # # # # # # # # # # # # #
|
|
|
+ # first stage - fast proposal network (pnet) to obtain face candidates
|
|
|
+ # # # # # # # # # # # # #
|
|
|
+
|
|
|
+ images_obj_per_resolution = {}
|
|
|
+
|
|
|
+ # TODO: use some type of rounding to number module 8 to increase probability that pyramid images will have the same resolution across input images
|
|
|
+
|
|
|
+ for index, scales in enumerate(all_scales):
|
|
|
+ h = images[index].shape[0]
|
|
|
+ w = images[index].shape[1]
|
|
|
+
|
|
|
+ for scale in scales:
|
|
|
+ hs = int(np.ceil(h * scale))
|
|
|
+ ws = int(np.ceil(w * scale))
|
|
|
+
|
|
|
+ if (ws, hs) not in images_obj_per_resolution:
|
|
|
+ images_obj_per_resolution[(ws, hs)] = []
|
|
|
+
|
|
|
+ im_data = imresample(images[index], (hs, ws))
|
|
|
+ im_data = (im_data - 127.5) * 0.0078125
|
|
|
+ img_y = np.transpose(im_data, (1, 0, 2)) # caffe uses different dimensions ordering
|
|
|
+ images_obj_per_resolution[(ws, hs)].append({'scale': scale, 'image': img_y, 'index': index})
|
|
|
+
|
|
|
+ for resolution in images_obj_per_resolution:
|
|
|
+ images_per_resolution = [i['image'] for i in images_obj_per_resolution[resolution]]
|
|
|
+ outs = pnet(images_per_resolution)
|
|
|
+
|
|
|
+ for index in range(len(outs[0])):
|
|
|
+ scale = images_obj_per_resolution[resolution][index]['scale']
|
|
|
+ image_index = images_obj_per_resolution[resolution][index]['index']
|
|
|
+ out0 = np.transpose(outs[0][index], (1, 0, 2))
|
|
|
+ out1 = np.transpose(outs[1][index], (1, 0, 2))
|
|
|
+
|
|
|
+ boxes, _ = generateBoundingBox(out1[:, :, 1].copy(), out0[:, :, :].copy(), scale, threshold[0])
|
|
|
+
|
|
|
+ # inter-scale nms
|
|
|
+ pick = nms(boxes.copy(), 0.5, 'Union')
|
|
|
+ if boxes.size > 0 and pick.size > 0:
|
|
|
+ boxes = boxes[pick, :]
|
|
|
+ images_with_boxes[image_index]['total_boxes'] = np.append(images_with_boxes[image_index]['total_boxes'],
|
|
|
+ boxes,
|
|
|
+ axis=0)
|
|
|
+
|
|
|
+ for index, image_obj in enumerate(images_with_boxes):
|
|
|
+ numbox = image_obj['total_boxes'].shape[0]
|
|
|
+ if numbox > 0:
|
|
|
+ h = images[index].shape[0]
|
|
|
+ w = images[index].shape[1]
|
|
|
+ pick = nms(image_obj['total_boxes'].copy(), 0.7, 'Union')
|
|
|
+ image_obj['total_boxes'] = image_obj['total_boxes'][pick, :]
|
|
|
+ regw = image_obj['total_boxes'][:, 2] - image_obj['total_boxes'][:, 0]
|
|
|
+ regh = image_obj['total_boxes'][:, 3] - image_obj['total_boxes'][:, 1]
|
|
|
+ qq1 = image_obj['total_boxes'][:, 0] + image_obj['total_boxes'][:, 5] * regw
|
|
|
+ qq2 = image_obj['total_boxes'][:, 1] + image_obj['total_boxes'][:, 6] * regh
|
|
|
+ qq3 = image_obj['total_boxes'][:, 2] + image_obj['total_boxes'][:, 7] * regw
|
|
|
+ qq4 = image_obj['total_boxes'][:, 3] + image_obj['total_boxes'][:, 8] * regh
|
|
|
+ image_obj['total_boxes'] = np.transpose(np.vstack([qq1, qq2, qq3, qq4, image_obj['total_boxes'][:, 4]]))
|
|
|
+ image_obj['total_boxes'] = rerec(image_obj['total_boxes'].copy())
|
|
|
+ image_obj['total_boxes'][:, 0:4] = np.fix(image_obj['total_boxes'][:, 0:4]).astype(np.int32)
|
|
|
+ dy, edy, dx, edx, y, ey, x, ex, tmpw, tmph = pad(image_obj['total_boxes'].copy(), w, h)
|
|
|
+
|
|
|
+ numbox = image_obj['total_boxes'].shape[0]
|
|
|
+ tempimg = np.zeros((24, 24, 3, numbox))
|
|
|
+
|
|
|
+ if numbox > 0:
|
|
|
+ for k in range(0, numbox):
|
|
|
+ tmp = np.zeros((int(tmph[k]), int(tmpw[k]), 3))
|
|
|
+ tmp[dy[k] - 1:edy[k], dx[k] - 1:edx[k], :] = images[index][y[k] - 1:ey[k], x[k] - 1:ex[k], :]
|
|
|
+ if tmp.shape[0] > 0 and tmp.shape[1] > 0 or tmp.shape[0] == 0 and tmp.shape[1] == 0:
|
|
|
+ tempimg[:, :, :, k] = imresample(tmp, (24, 24))
|
|
|
+ else:
|
|
|
+ return np.empty()
|
|
|
+
|
|
|
+ tempimg = (tempimg - 127.5) * 0.0078125
|
|
|
+ image_obj['rnet_input'] = np.transpose(tempimg, (3, 1, 0, 2))
|
|
|
+
|
|
|
+ # # # # # # # # # # # # #
|
|
|
+ # second stage - refinement of face candidates with rnet
|
|
|
+ # # # # # # # # # # # # #
|
|
|
+
|
|
|
+ bulk_rnet_input = np.empty((0, 24, 24, 3))
|
|
|
+ for index, image_obj in enumerate(images_with_boxes):
|
|
|
+ if 'rnet_input' in image_obj:
|
|
|
+ bulk_rnet_input = np.append(bulk_rnet_input, image_obj['rnet_input'], axis=0)
|
|
|
+
|
|
|
+ out = rnet(bulk_rnet_input)
|
|
|
+ out0 = np.transpose(out[0])
|
|
|
+ out1 = np.transpose(out[1])
|
|
|
+ score = out1[1, :]
|
|
|
+
|
|
|
+ i = 0
|
|
|
+ for index, image_obj in enumerate(images_with_boxes):
|
|
|
+ if 'rnet_input' not in image_obj:
|
|
|
+ continue
|
|
|
+
|
|
|
+ rnet_input_count = image_obj['rnet_input'].shape[0]
|
|
|
+ score_per_image = score[i:i + rnet_input_count]
|
|
|
+ out0_per_image = out0[:, i:i + rnet_input_count]
|
|
|
+
|
|
|
+ ipass = np.where(score_per_image > threshold[1])
|
|
|
+ image_obj['total_boxes'] = np.hstack([image_obj['total_boxes'][ipass[0], 0:4].copy(),
|
|
|
+ np.expand_dims(score_per_image[ipass].copy(), 1)])
|
|
|
+
|
|
|
+ mv = out0_per_image[:, ipass[0]]
|
|
|
+
|
|
|
+ if image_obj['total_boxes'].shape[0] > 0:
|
|
|
+ h = images[index].shape[0]
|
|
|
+ w = images[index].shape[1]
|
|
|
+ pick = nms(image_obj['total_boxes'], 0.7, 'Union')
|
|
|
+ image_obj['total_boxes'] = image_obj['total_boxes'][pick, :]
|
|
|
+ image_obj['total_boxes'] = bbreg(image_obj['total_boxes'].copy(), np.transpose(mv[:, pick]))
|
|
|
+ image_obj['total_boxes'] = rerec(image_obj['total_boxes'].copy())
|
|
|
+
|
|
|
+ numbox = image_obj['total_boxes'].shape[0]
|
|
|
+
|
|
|
+ if numbox > 0:
|
|
|
+ tempimg = np.zeros((48, 48, 3, numbox))
|
|
|
+ image_obj['total_boxes'] = np.fix(image_obj['total_boxes']).astype(np.int32)
|
|
|
+ dy, edy, dx, edx, y, ey, x, ex, tmpw, tmph = pad(image_obj['total_boxes'].copy(), w, h)
|
|
|
+
|
|
|
+ for k in range(0, numbox):
|
|
|
+ tmp = np.zeros((int(tmph[k]), int(tmpw[k]), 3))
|
|
|
+ tmp[dy[k] - 1:edy[k], dx[k] - 1:edx[k], :] = images[index][y[k] - 1:ey[k], x[k] - 1:ex[k], :]
|
|
|
+ if tmp.shape[0] > 0 and tmp.shape[1] > 0 or tmp.shape[0] == 0 and tmp.shape[1] == 0:
|
|
|
+ tempimg[:, :, :, k] = imresample(tmp, (48, 48))
|
|
|
+ else:
|
|
|
+ return np.empty()
|
|
|
+ tempimg = (tempimg - 127.5) * 0.0078125
|
|
|
+ image_obj['onet_input'] = np.transpose(tempimg, (3, 1, 0, 2))
|
|
|
+
|
|
|
+ i += rnet_input_count
|
|
|
+
|
|
|
+ # # # # # # # # # # # # #
|
|
|
+ # third stage - further refinement and facial landmarks positions with onet
|
|
|
+ # # # # # # # # # # # # #
|
|
|
+
|
|
|
+ bulk_onet_input = np.empty((0, 48, 48, 3))
|
|
|
+ for index, image_obj in enumerate(images_with_boxes):
|
|
|
+ if 'onet_input' in image_obj:
|
|
|
+ bulk_onet_input = np.append(bulk_onet_input, image_obj['onet_input'], axis=0)
|
|
|
+
|
|
|
+ out = onet(bulk_onet_input)
|
|
|
+
|
|
|
+ out0 = np.transpose(out[0])
|
|
|
+ out1 = np.transpose(out[1])
|
|
|
+ out2 = np.transpose(out[2])
|
|
|
+ score = out2[1, :]
|
|
|
+ points = out1
|
|
|
+
|
|
|
+ i = 0
|
|
|
+ ret = []
|
|
|
+ for index, image_obj in enumerate(images_with_boxes):
|
|
|
+ if 'onet_input' not in image_obj:
|
|
|
+ ret.append(None)
|
|
|
+ continue
|
|
|
+
|
|
|
+ onet_input_count = image_obj['onet_input'].shape[0]
|
|
|
+
|
|
|
+ out0_per_image = out0[:, i:i + onet_input_count]
|
|
|
+ score_per_image = score[i:i + onet_input_count]
|
|
|
+ points_per_image = points[:, i:i + onet_input_count]
|
|
|
+
|
|
|
+ ipass = np.where(score_per_image > threshold[2])
|
|
|
+ points_per_image = points_per_image[:, ipass[0]]
|
|
|
+
|
|
|
+ image_obj['total_boxes'] = np.hstack([image_obj['total_boxes'][ipass[0], 0:4].copy(),
|
|
|
+ np.expand_dims(score_per_image[ipass].copy(), 1)])
|
|
|
+ mv = out0_per_image[:, ipass[0]]
|
|
|
+
|
|
|
+ w = image_obj['total_boxes'][:, 2] - image_obj['total_boxes'][:, 0] + 1
|
|
|
+ h = image_obj['total_boxes'][:, 3] - image_obj['total_boxes'][:, 1] + 1
|
|
|
+ points_per_image[0:5, :] = np.tile(w, (5, 1)) * points_per_image[0:5, :] + np.tile(
|
|
|
+ image_obj['total_boxes'][:, 0], (5, 1)) - 1
|
|
|
+ points_per_image[5:10, :] = np.tile(h, (5, 1)) * points_per_image[5:10, :] + np.tile(
|
|
|
+ image_obj['total_boxes'][:, 1], (5, 1)) - 1
|
|
|
+
|
|
|
+ if image_obj['total_boxes'].shape[0] > 0:
|
|
|
+ image_obj['total_boxes'] = bbreg(image_obj['total_boxes'].copy(), np.transpose(mv))
|
|
|
+ pick = nms(image_obj['total_boxes'].copy(), 0.7, 'Min')
|
|
|
+ image_obj['total_boxes'] = image_obj['total_boxes'][pick, :]
|
|
|
+ points_per_image = points_per_image[:, pick]
|
|
|
+
|
|
|
+ ret.append((image_obj['total_boxes'], points_per_image))
|
|
|
+ else:
|
|
|
+ ret.append(None)
|
|
|
+
|
|
|
+ i += onet_input_count
|
|
|
+
|
|
|
+ return ret
|
|
|
+
|
|
|
+
|
|
|
+# function [boundingbox] = bbreg(boundingbox,reg)
|
|
|
+def bbreg(boundingbox,reg):
|
|
|
+ # calibrate bounding boxes
|
|
|
+ if reg.shape[1]==1:
|
|
|
+ reg = np.reshape(reg, (reg.shape[2], reg.shape[3]))
|
|
|
+
|
|
|
+ w = boundingbox[:,2]-boundingbox[:,0]+1
|
|
|
+ h = boundingbox[:,3]-boundingbox[:,1]+1
|
|
|
+ b1 = boundingbox[:,0]+reg[:,0]*w
|
|
|
+ b2 = boundingbox[:,1]+reg[:,1]*h
|
|
|
+ b3 = boundingbox[:,2]+reg[:,2]*w
|
|
|
+ b4 = boundingbox[:,3]+reg[:,3]*h
|
|
|
+ boundingbox[:,0:4] = np.transpose(np.vstack([b1, b2, b3, b4 ]))
|
|
|
+ return boundingbox
|
|
|
+
|
|
|
+def generateBoundingBox(imap, reg, scale, t):
|
|
|
+ # use heatmap to generate bounding boxes
|
|
|
+ stride=2
|
|
|
+ cellsize=12
|
|
|
+
|
|
|
+ imap = np.transpose(imap)
|
|
|
+ dx1 = np.transpose(reg[:,:,0])
|
|
|
+ dy1 = np.transpose(reg[:,:,1])
|
|
|
+ dx2 = np.transpose(reg[:,:,2])
|
|
|
+ dy2 = np.transpose(reg[:,:,3])
|
|
|
+ y, x = np.where(imap >= t)
|
|
|
+ if y.shape[0]==1:
|
|
|
+ dx1 = np.flipud(dx1)
|
|
|
+ dy1 = np.flipud(dy1)
|
|
|
+ dx2 = np.flipud(dx2)
|
|
|
+ dy2 = np.flipud(dy2)
|
|
|
+ score = imap[(y,x)]
|
|
|
+ reg = np.transpose(np.vstack([ dx1[(y,x)], dy1[(y,x)], dx2[(y,x)], dy2[(y,x)] ]))
|
|
|
+ if reg.size==0:
|
|
|
+ reg = np.empty((0,3))
|
|
|
+ bb = np.transpose(np.vstack([y,x]))
|
|
|
+ q1 = np.fix((stride*bb+1)/scale)
|
|
|
+ q2 = np.fix((stride*bb+cellsize-1+1)/scale)
|
|
|
+ boundingbox = np.hstack([q1, q2, np.expand_dims(score,1), reg])
|
|
|
+ return boundingbox, reg
|
|
|
+
|
|
|
+# function pick = nms(boxes,threshold,type)
|
|
|
+def nms(boxes, threshold, method):
|
|
|
+ if boxes.size==0:
|
|
|
+ return np.empty((0,3))
|
|
|
+ x1 = boxes[:,0]
|
|
|
+ y1 = boxes[:,1]
|
|
|
+ x2 = boxes[:,2]
|
|
|
+ y2 = boxes[:,3]
|
|
|
+ s = boxes[:,4]
|
|
|
+ area = (x2-x1+1) * (y2-y1+1)
|
|
|
+ I = np.argsort(s)
|
|
|
+ pick = np.zeros_like(s, dtype=np.int16)
|
|
|
+ counter = 0
|
|
|
+ while I.size>0:
|
|
|
+ i = I[-1]
|
|
|
+ pick[counter] = i
|
|
|
+ counter += 1
|
|
|
+ idx = I[0:-1]
|
|
|
+ xx1 = np.maximum(x1[i], x1[idx])
|
|
|
+ yy1 = np.maximum(y1[i], y1[idx])
|
|
|
+ xx2 = np.minimum(x2[i], x2[idx])
|
|
|
+ yy2 = np.minimum(y2[i], y2[idx])
|
|
|
+ w = np.maximum(0.0, xx2-xx1+1)
|
|
|
+ h = np.maximum(0.0, yy2-yy1+1)
|
|
|
+ inter = w * h
|
|
|
+ if method is 'Min':
|
|
|
+ o = inter / np.minimum(area[i], area[idx])
|
|
|
+ else:
|
|
|
+ o = inter / (area[i] + area[idx] - inter)
|
|
|
+ I = I[np.where(o<=threshold)]
|
|
|
+ pick = pick[0:counter]
|
|
|
+ return pick
|
|
|
+
|
|
|
+# function [dy edy dx edx y ey x ex tmpw tmph] = pad(total_boxes,w,h)
|
|
|
+def pad(total_boxes, w, h):
|
|
|
+ # compute the padding coordinates (pad the bounding boxes to square)
|
|
|
+ tmpw = (total_boxes[:,2]-total_boxes[:,0]+1).astype(np.int32)
|
|
|
+ tmph = (total_boxes[:,3]-total_boxes[:,1]+1).astype(np.int32)
|
|
|
+ numbox = total_boxes.shape[0]
|
|
|
+
|
|
|
+ dx = np.ones((numbox), dtype=np.int32)
|
|
|
+ dy = np.ones((numbox), dtype=np.int32)
|
|
|
+ edx = tmpw.copy().astype(np.int32)
|
|
|
+ edy = tmph.copy().astype(np.int32)
|
|
|
+
|
|
|
+ x = total_boxes[:,0].copy().astype(np.int32)
|
|
|
+ y = total_boxes[:,1].copy().astype(np.int32)
|
|
|
+ ex = total_boxes[:,2].copy().astype(np.int32)
|
|
|
+ ey = total_boxes[:,3].copy().astype(np.int32)
|
|
|
+
|
|
|
+ tmp = np.where(ex>w)
|
|
|
+ edx.flat[tmp] = np.expand_dims(-ex[tmp]+w+tmpw[tmp],1)
|
|
|
+ ex[tmp] = w
|
|
|
+
|
|
|
+ tmp = np.where(ey>h)
|
|
|
+ edy.flat[tmp] = np.expand_dims(-ey[tmp]+h+tmph[tmp],1)
|
|
|
+ ey[tmp] = h
|
|
|
+
|
|
|
+ tmp = np.where(x<1)
|
|
|
+ dx.flat[tmp] = np.expand_dims(2-x[tmp],1)
|
|
|
+ x[tmp] = 1
|
|
|
+
|
|
|
+ tmp = np.where(y<1)
|
|
|
+ dy.flat[tmp] = np.expand_dims(2-y[tmp],1)
|
|
|
+ y[tmp] = 1
|
|
|
+
|
|
|
+ return dy, edy, dx, edx, y, ey, x, ex, tmpw, tmph
|
|
|
+
|
|
|
+# function [bboxA] = rerec(bboxA)
|
|
|
+def rerec(bboxA):
|
|
|
+ # convert bboxA to square
|
|
|
+ h = bboxA[:,3]-bboxA[:,1]
|
|
|
+ w = bboxA[:,2]-bboxA[:,0]
|
|
|
+ l = np.maximum(w, h)
|
|
|
+ bboxA[:,0] = bboxA[:,0]+w*0.5-l*0.5
|
|
|
+ bboxA[:,1] = bboxA[:,1]+h*0.5-l*0.5
|
|
|
+ bboxA[:,2:4] = bboxA[:,0:2] + np.transpose(np.tile(l,(2,1)))
|
|
|
+ return bboxA
|
|
|
+
|
|
|
+def imresample(img, sz):
|
|
|
+ im_data = cv2.resize(img, (sz[1], sz[0]), interpolation=cv2.INTER_AREA) #@UndefinedVariable
|
|
|
+ return im_data
|
|
|
+
|
|
|
+ # This method is kept for debugging purpose
|
|
|
+# h=img.shape[0]
|
|
|
+# w=img.shape[1]
|
|
|
+# hs, ws = sz
|
|
|
+# dx = float(w) / ws
|
|
|
+# dy = float(h) / hs
|
|
|
+# im_data = np.zeros((hs,ws,3))
|
|
|
+# for a1 in range(0,hs):
|
|
|
+# for a2 in range(0,ws):
|
|
|
+# for a3 in range(0,3):
|
|
|
+# im_data[a1,a2,a3] = img[int(floor(a1*dy)),int(floor(a2*dx)),a3]
|
|
|
+# return im_data
|
|
|
+
|

 zangruirui
zangruirui
{kind=link}
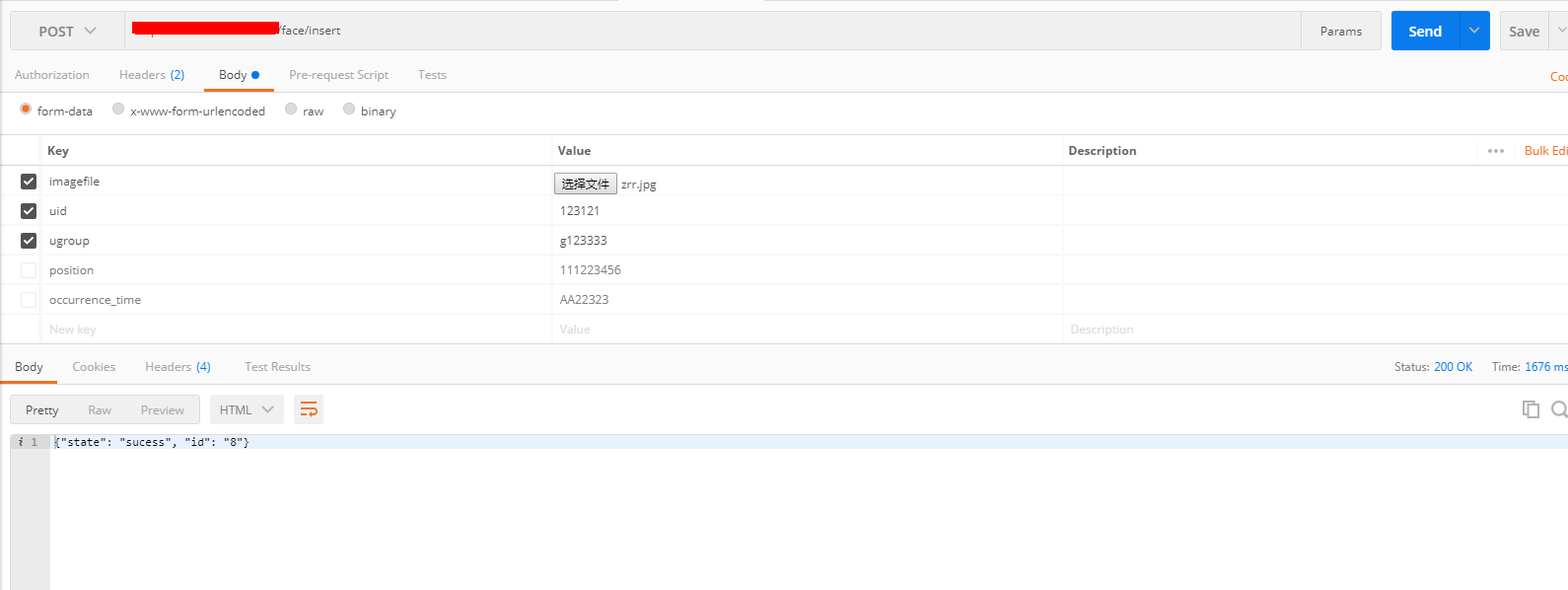
{kind=link}
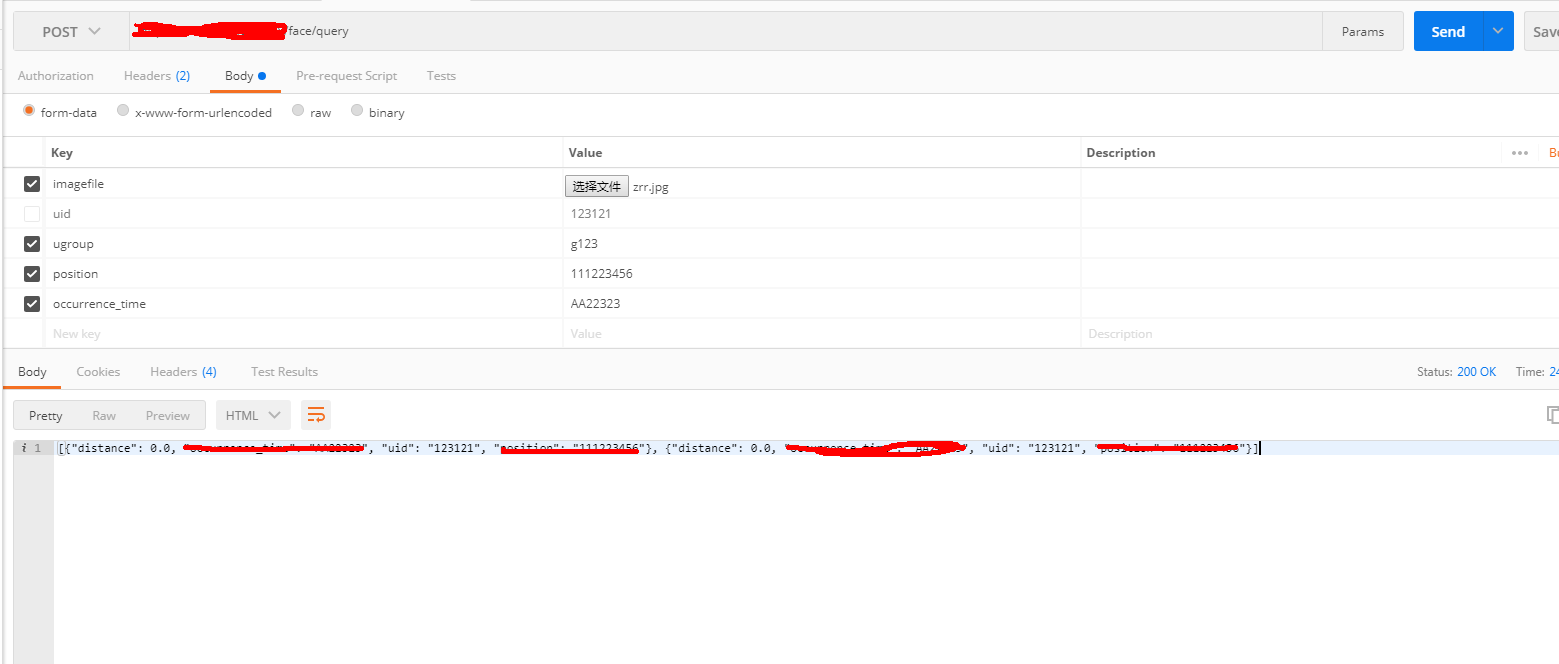
{kind=link}